

The Data Valuation Paradox
Malt Liquidity 136

In the information age, the quickest way to get labeled a Luddite is to express the belief that data is not valuable. How could data — the new oil — not be valuable? How could more of it not be better? Since data is valuable, then of course the data you own must hold some value too. Haven’t you seen how much Google and Meta are worth by selling your data? (~$2 trillion and ~$1.1 trillion respectively.) And yet, there’s no cohesive, rigorous definition of how exactly your data should be valued, if at all, or what “owning your data” even means. To properly protect our data, then, we need a clearer idea of what those concepts mean.
It wouldn’t be a controversial statement to say that humans are bad at math. Indeed, there’s a high chance that, if you sit through enough happy hours, a lawyer you run into will make a quip along the lines of “we’re lawyers, we’re not good at math.” (Why are people alright saying this? People don’t say “I can’t read, isn’t that funny?” to be relatable). Surprisingly, this is a somewhat reductive perspective. Certainly, without training or talent, humans are innately not very good with large numbers, understanding probabilities, and knowing when statistics can be applied. In the current environment, numbers are thrown at us nonstop, such as political polls, tip percentages, studies telling us stuff, stock prices, and more. We are surrounded by them, and it’s easy to get overwhelmed.
However, humans have uniquely strong skills rooted in our intuition that are definitely mathematical. It’s not an exaggeration to label the human brain as the greatest pattern recognition machine to ever exist. We can contextualize relative quantities at a glance without ever consciously processing them — it’s the difference between choosing a larger pizza slice and guessing how many jellybeans are in a jar to win a prize. This scales to complex three-dimensional physics as well, as anyone who has hit a nice approach shot onto a green or made contact on a curveball would know. The overarching point is that humans have a ridiculous intuitive ability to approximate and extrapolate — isn’t that exactly what probability and statistics attempt to do?
The divergence between math and humans arises due to intent, methodology, and scalability. Applied probabilistic and statistical methods are just processes that can be optimally applied to certain problems. Which method you apply depends on factors such as the level of precision desired, availability, amount, and cleanliness of data, and how fast you want the result. Humans apply this type of thinking contextually. Beyond specialized activities, this usually means that these capabilities are only used when relevant to the individual. Humans are also creatures of evolution — these capacities were developed many millennia before the advent of computing. Here lies the crux of the confusion: human thinking was never meant to scale with the amount of data available. Rather, human intuition was honed on balancing accuracy relative to the available information and the speed with which the estimate needed to be made. Human ability is unparalleled when an approximation needs to be made on very little data, which is why casino games trap so many people. Humans simply cannot process the “long run” without putting it in the context of themselves without training the instinct out, which is why you can find endless amounts of people convinced that they’ve “solved” roulette that hawk “their strategies”.
Accordingly, the human perspective regarding “data being the new oil” frames the concept of value as an inherent property of the data being produced. This implies that the ever-increasing amount of data collected represents more inherent value being produced, whether it’s a function of getting more people online, recording an increasing amount of miles driven, or allowing more tracking of what people do online (anecdotally, I recently visited a news site and was prompted to accept all cookies necessary for 692 partners.) This isn’t entirely inaccurate — certainly, the proliferation of data collection has produced many novel datasets. But data is not a finite resource, like oil. The value of data is not a linear function of volume, but rather a derivative of what the data produces. Consequently, if data is to be valuable at scale, it needs to correspond with a method of utilization that benefits from scale.
A common misconception is that “data science” is new math. One of the most commonly used methods to assess correlation between data, Pearson R, dates back to the late 18th century and was formalized by Karl Pearson in the early 1900s. Least squares regression, perhaps the basis of the entire field of applied statistics, was first published by Legendre in 1805 and claimed by Gauss in 1809, though there is a significant amount of discussion as to who the “true” credit belongs to. Statistics is squarely in the applied math realm, where generalized, theoretical statements originated from a desire to utilize a set of data. (Compare this to number theory, which is pure theoretical constructs that have no bearing to reality until accidentally applied, and convinced me that some form of divine inspiration exists.)

Least squares originated from the field of astronomy, where mathematicians sought to find methods to extrapolate observed data to better understand the workings of Earth and other celestial bodies. Of course, the limit of these methods was that the data had to be manually recorded and preserved and the calculations had to be done by hand or with a mechanical calculator.
However, record-keeping has been a core practice throughout human history, and historical datasets still have use today. My favorite historical dataset is baseball statistics, where a remarkably robust log of player performance tracking started in the 19th century itself. Baseball is a great example as to how computers changed the field of statistics, as the digitization of historical records in the 1960s suddenly made all sorts of calculations and modeling possible on an extraordinary scale. Since the record-keeping was so thorough and the games were so numerous, calculations could be made that led to a better understanding of what data wasn’t being collected that could have some utility, which led to “sabermetrics”, the baseball-specific term for querying basic numerical observations (hits, batting average, strikeouts) and advanced observations derived from basic numerical observations (weighted on-base average) to play the game more optimally.
The advent of computing and its exponential progress to its current state has proven that the amount of data dramatically improves the efficacy and application of statistical methods. This also had the effect of “dehumanizing” approximation to some extent — Gauss and Legendre were using the same methods as baseball statisticians, but with far fewer datapoints. Baseball neatly highlights the value of sample size — if I have thousands of games, I can be much more certain that the conclusion drawn from a statistic is indicative than if I’ve watched 4 games and concluded something else. Herein lies the data valuation paradox: the statistical value of the dataset increases logarithmically with size while the individual entry’s value decays exponentially. Put more simply: a single significant observation does not exist in a statistically significant dataset. This is a core implication of the statement “statistics do not apply to individuals in a population” and why computational statistics diverges so heavily from human intuition — they’re fundamentally two different things entirely. On an individual level, in some sense, the old joke “it’s 50/50 — either it happens or it doesn’t” is not a wholly invalid method of reasoning in some situations, though when taken to the extreme of “flipism”, it becomes comic book material.
The paradox gives rise to multiple conditions that must be part of data valuation:
1) After a certain threshold, the size of the dataset no longer materially impacts the value of the dataset
2) The cleanliness and comprehensiveness of the dataset both impacts the value and must be maintained to preserve its value
Comprehensiveness’ value should be a fairly obvious: the data must envelop the population it purports to represent so all tail outcomes and future developments can be captured and synthesized. Once again, we turn to baseball (truly the statistician’s game) — if a rule change significantly alters the game and changes the distribution of outcomes that follow it, a dataset that doesn’t include them will not only lack perspective on the quantified impact of the rule change, but also could invalidate significant conclusions drawn from the old dataset. Depending on the significance, this adds an element of negative value to outdated information rather than just zeroing it.
Cleanliness, on the other hand, is a more esoteric judgment. Logically, one can conclude that it is impossible to manually examine and verify every entry in computer-age datasets. Every raw dataset will have some errors: null entries, incorrect or obfuscated entries, and extreme outliers are some common ones. A clean raw dataset would be one where the data is reliably accumulated in a standardized format with minimal errors. An overall clean dataset would not only have the obvious errors removed, but also would have subjectively culled entries that distort the data while preserving the representative property of the raw data. (Indeed, when programmatically analyzing data, most of the effort is spent cleaning it — the math step is primarily a runtime process nowadays thanks to the robustness of open-source libraries having written the actual coded math for you. Both types of cleanliness reflect skill in maintaining quality mechanisms for data collection and curative techniques to optimize the data for analysis. Thus, the value created by cleanliness is a function of the cost of the mechanisms and the difficulty and quality of the labor involved.
While these elements all make up the intrinsic value of data, a practical truth must be addressed: the theoretical value of a dataset is worth nothing if nobody will buy it from you at an actual price, which makes sense — what good is a clean dataset if nothing conclusive can be drawn from it, or the conclusions derived have no useful applicability? This gives rise to the concept of extrinsic value: data can only be valuable if there is some expected gain of utility as a result of owning it. Extrinsic value is not only an expected value calculation (here, the probability of utility being found weighted by the realizable gain as a result of finding that outcome) but an exclusivity consideration. Having an exclusive database that others could use to encroach on your operations, thereby reducing your profit or knowledge advantage, creates positive value due to the potential negative utility if publicly given out. If the data is so critical to another’s operations such that it’s worth acquiring, Coasean bargaining outlines the idea that a fair value price exists for a data sharing agreement between the data holder and the acquirer, generating an optimal outcome for both parties.
Putting all of this together, we get a concrete idea of how data is valued, outlined by the following framework:
1) For data to have any monetary value whatsoever, there must be some potential expected utility realizable due to owning the data. Direct monetization, exclusivity limiting competitor’s ability to monetize and gain market share, or tangible benefits contributing to increased performance that have indirect positive monetary externalities (for example, a novel baseball dataset that leads to overall hitting strategy improvement would help win more games which drives more demand for tickets) must exist to arrive at a numerical valuation. We can call this “extrinsic value”. Note that extrinsic value can be approximated in the case of exclusivity to value internal, proprietary data (“negative utility” pricing as outlined above.)
2) Given the existence of extrinsic value, the intrinsic factors of size, comprehensiveness, and cleanliness can be considered to further modify the value of the data. Ability to maintain this dataset can also factor in (exemplified by X/Twitter’s API policy changes, which heavily reduced the ability of bots to scrape data from the website without paying them a pound of flesh, thereby creating exclusivity in their own ability to maintain a comprehensive post-API change database.)
It's plainly obvious that a random individual user’s entry in all these datasets is immaterial due to the sheer volume and scale of data. For example, X currently has ~500 million worldwide users. A dataset would lose virtually no utility if tens of millions of average user accounts were removed from it. (In fact, given the botting, spam, and AI-generated posting on the site, this is probably necessary to make the data usable in any way.) However, specific individual entries (or sets attached to them) could have seriously outsized value. Would a Twitter dataset be complete without all of the engagement metrics and posts associated with Donald Trump? For companies dependent on user engagement, quantifying exactly how much engagement driven is imperative for capturing value through operations.
An even better case study is Netflix, where user data determines everything about how the business is run. Consider the recent anecdote described by the director Brian Helgeland, where he describes a pitch made to Netflix regarding a potential sequel to A Knight’s Tale. Netflix, after running some predictive analysis using its user engagement metrics, decided the sequel wouldn’t be worth producing after looking at the output. Since Netflix doesn’t charge to view specific content, they clearly developed some metric that approximates the dollar value of the viewership growth curve, which probably factors in the amount of initial views/probability of hitting the “trending top 10”, the likelihood of repeated viewings, potential subscribers gained/unsubscribes prevented, genre, and more. If potential content is unlikely to deliver the value of its budget by their metrics, then they scrap the content. Thus, their exclusive viewership data could be valued as some combination of approximate savings from not producing unviewed content + approximate gains from producing content that went viral and smashed the predicted expected value.
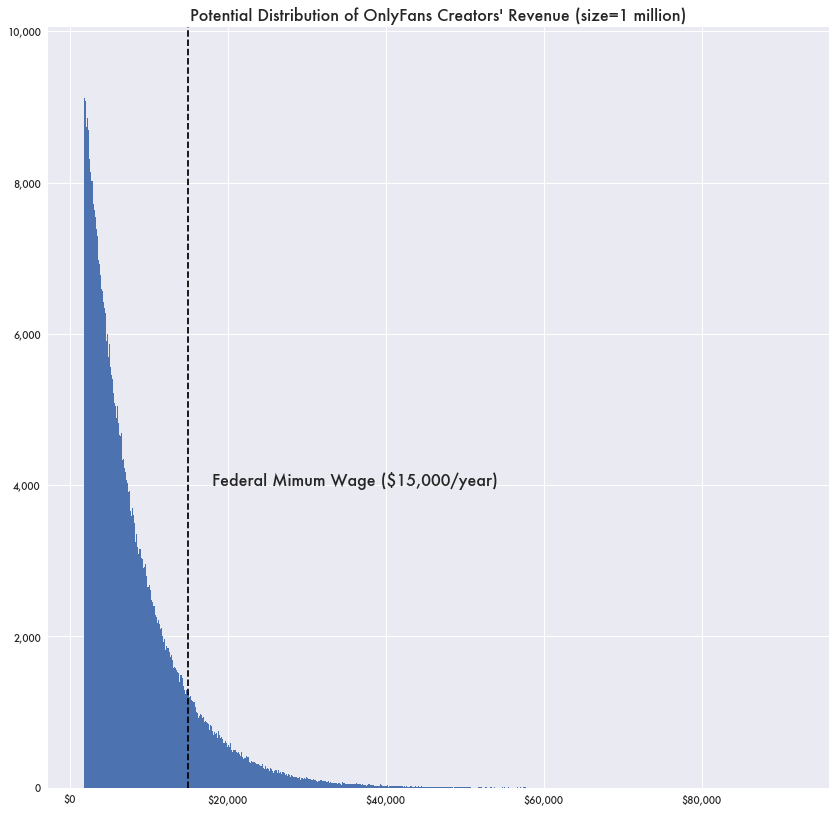
This neatly raises the topic of individual data ownership. It’s unlikely that anyone would argue that Netflix owes some sort of compensation for utilizing subscriber viewership data in this way — after all, the subscription fee and the content you watch is the direct benefit received, with the data being put to use to optimize the creation of content that you want to watch, and it’s not like users are funding or producing the content available for viewing. In the case of user-created content, however, there is a palpable feeling that the content couldn’t exist without the user. However, platforms like X are built around user content, and though significant users can monetize their profile in a variety of ways, the sites make use of all the engagement data to build profiles of viewers to sell advertisements. X took the step of compensating its biggest users as an incentive to keep posting by sharing revenue from the ads shown when their posts are engaged with, which assuaged the power users that drive the site. For X, this valuation method works easier because the distribution of valuable users is heavily skewed. Social media followings on sites like X follow power law distributions, where a vast majority of the accounts have little-to-no following and receive/create little-to-no value, best visualized through OnlyFans revenue:
Various creators from the adult content website OnlyFans have described earning thousands of dollars a day through the service. . . Based on annual reports from the company’s parent firm, Fenix International, in 2022 OnlyFans had 3.18 million creators who brought in $5.55 billion in revenue. Large numbers indeed, but that works out to an average annual revenue before taxes and fees of $1,744. It’s possible to create a heavily skewed distribution modeling the OnlyFans’ data like this using 1 million earners where at least one person earns $100,000 in a year and the average income is $1,744.
However, on sites like Google, Facebook, and Instagram, there’s a palpable sense that the user is being taken advantage of, as there’s no real monetary value directly realized around your specific search results or viewing content that your specific friends post. As the old joke goes — if the product is free, you’re the product. After all, targeted advertising is like an unwanted Netflix content analysis algorithm — they know what you want to see and sell that information, but you didn’t sign up for it and you don’t know who that data is being sold to. This sense of unease bubbled for a while, but the controversy truly climaxed after the Cambridge Analytica scandal broke in 2018, after which Facebook had to pay a 725 million dollar class action settlement to settle claims that it violated user privacy by granting third-parties access to certain private user data from the time period between May 2007 and December 2022.
Consequently, data privacy regulations that governed the usage of data like the European Union’s General Data Protection Regulation and California’s equivalent California Consumer Privacy Act gained power to dictate the terms with which user data had to be used by. The rate of regulation has only accelerated in Europe, with increased fines threatened and the core business practices of search and advertising having to contort itself to stricter and harsher regulation. The net effect, as I like to joke, has essentially rendered the EU’s tech sector the equivalent of “popups and fining American companies”, as evidenced by the size of the respective market capitalizations in publicly traded tech stocks.
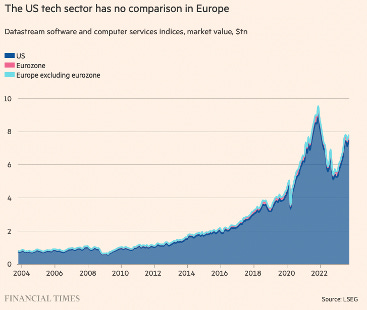
(Note that the chart doesn’t include the entire runup of AI stocks in 2023-24 such as NVDA, meaning that this gap has widened significantly.)
Is it really fair to feel a right to “ownership” and “protection” of our user data if the product and platform is free, though? Surely seeing products that you might want to buy is preferable to getting random junk catered to a wide audience with no discernible cohesion. For example, back in the days where you still had to watch television live, I used to stay up late and watch Comedy Central. As a teenager, I have a vivid memory of every single ad break after 10:00 PM being filled with phone sex lines and infomercials for random products. Even today, if I turn on the radio, I can’t drive more than 15 minutes without hearing a blaring jingle for the local area’s biggest billboard Saul Goodman-esque personal injury attorney. The quid pro quo of a usable search engine and a platform to keep up to date with our connections for the ability to monetize the user data isn’t an unfair tradeoff mathematically. The problem comes in that the human contextualization of statistics thinks that it’s us personally that is being targeted, rather than a demographic — it feels like somebody’s watching me, and I have no privacy, as the famous 1984 song goes. It’s not really a joke anymore, but simply the reality we live in — pretty much everything surrounding the government’s PRISM program that was the basis of Edward Snowden’s whistleblowing in 2013 is pretty much assumed to be a core part of reality at this point. Of course, tech capacity has only exponentially grown since then.
Still, it feels like there is some corrective remedy out there. Most data sharing, production, and value capture deliver a tangible value to the individual producing it or allowing its utilization: the baseball player gets compensated for every recorded at-bat through salary, the Netflix user has the choice of unsubscribing if the content no longer caters to their desires, and the recorded miles driven of a modern-day electric car helps refine the self-driving capacity for all Tesla owners. Even the understanding that being an individual in a big data set is essentially hiding in plain sight is not comforting given that it only takes a few distinct identifiers to track down exactly who you are unless the data is altered specifically to mask the individual. Completely logging off is not feasible to remain gainfully employed and is much, much harder than one would imagine, as evidenced by a reporter struggling to even go 24 hours without touching Big Tech products in the course of a normal day. And certainly, endless popups do nothing to assuage these concerns and annoy everyone involved.
My proposal for compensation primarily addresses the existential concern of feeling that one has value when the math and algorithms clearly cannot place anything more than an infinitesimal, essentially zero-bounded value on one’s data entry in these “you are the product” situations. If you could structure a similar system to the concept of payment for order flow in finance, where individuals are compensated for directing their stock trades or credit card spending through a form of rebate (tighter spreads, credit card points) without destroying the entire targeted advertising industry (which does subsidize a great many number of products), this would temper some of the frustration driven by it.
My idea is to create a compensation scheme required of all AdTech businesses over a certain size (say, $100mm) where, each time an individual’s data is sold in a certain manner, an allocation of a token is distributed for them to claim. This token doesn’t have to denominate anything or have any practical utility — as evidenced by DogeCoin, which holds a 22 billion dollar market capitalization, all it has to do is exist for some users to value it. To claim the coin, each user can create their own unique address similar to ENS domains.
This creates the amusing, absurd circumstance where users can then find a way to stack-rank how much their data is being utilized and making a game out of the situation. Eventually, this could create a different method of valuing user profiles such that mass data collection for targeting wouldn’t even be necessary, similar to how the rise of social media influencers created the organic marketing pipeline. Regulations create compliance costs which are passed down to users either through more ad-stuffing or direct charges — by creating a quasi-market, however, we can let the market figure out how to fairly compensate users. The beauty of the current market state is that it doesn’t matter what the “real value” of something is — DogeCoin and various cryptocurrencies prove that there’s no need for a real-world use case for something to hold value in the eyes of the users. (It’s not a coincidence that I picked DogeCoin — back in the early days of Reddit, you could “tip” another user using DogeCoin when it was worthless. Of course, after it became valuable, this practice went away.) In a way, that’s the trick to solving user compensation — as long as it’s valued in something, it won’t feel to the individual like they’re worth nothing. At least it’s better than clicking yet another popup.